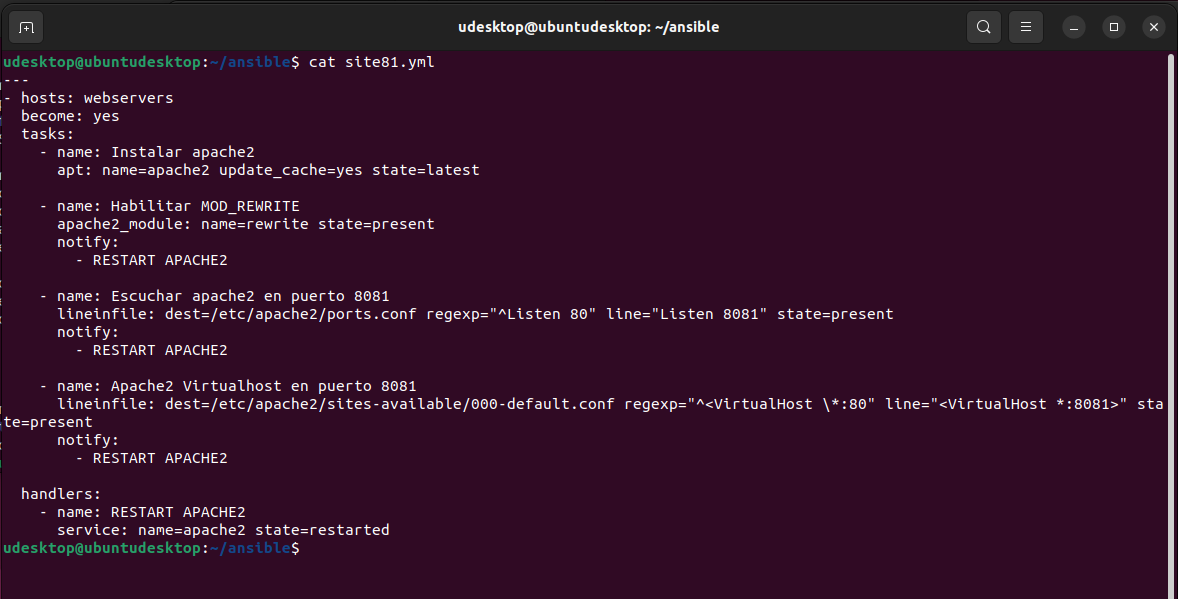
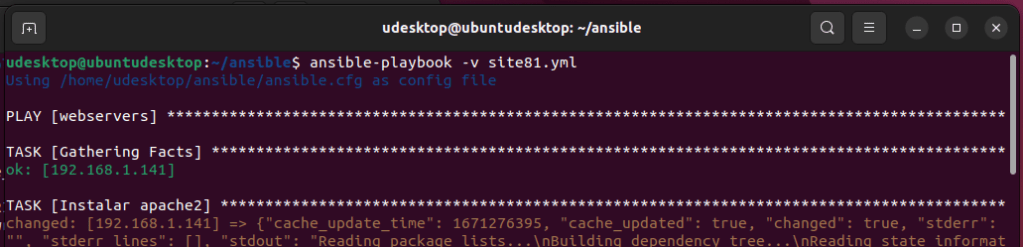
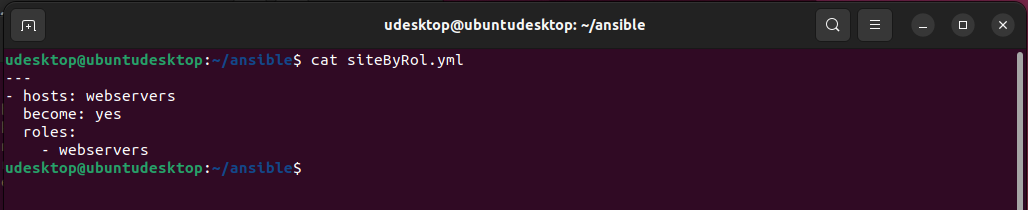
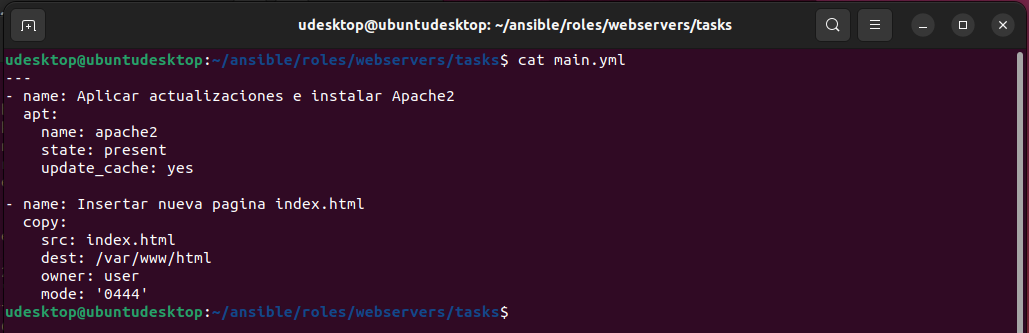
Casi todo el contenido lo he sacado de este video de Youtube <SI NO SABES USAR GIT, CON ESTE VIDEO APRENDES.> del canal de La Chica de Sistemas, el cual recomiendo visitar.
Loguearse en Git
En mi caso estoy dado de alta en Github.com
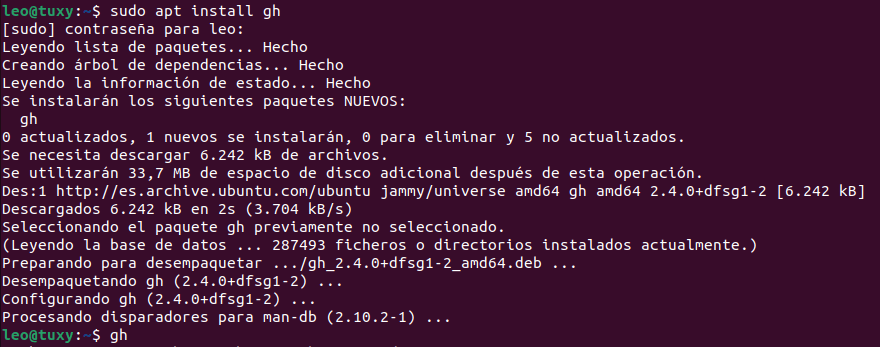
Instalar Git cli
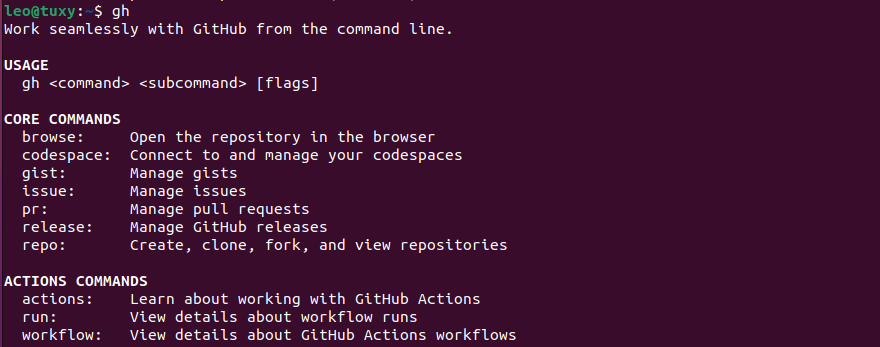
Para ver una pequeña ayuda escribe gh
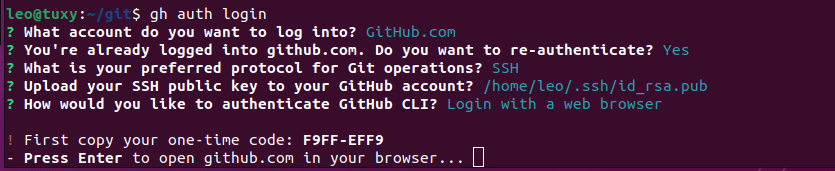
Para loguearse lo hacemos con gh auth login. En la cuenta seleccionamos Githuh.com
En el protocolo para operar selecciono SSH
En la clave pública selecciono id_rsa.pub
En como me gustaría autenticar selecciono con un navegador
Me da un código para copiar en el navegador y una vez que presiono Enter se abre una página nueva donde escribo el código. Pinchar en Continuar y autorizar Github.
Una vez terminado ya estas logueado en Github.
Crear un repositorio
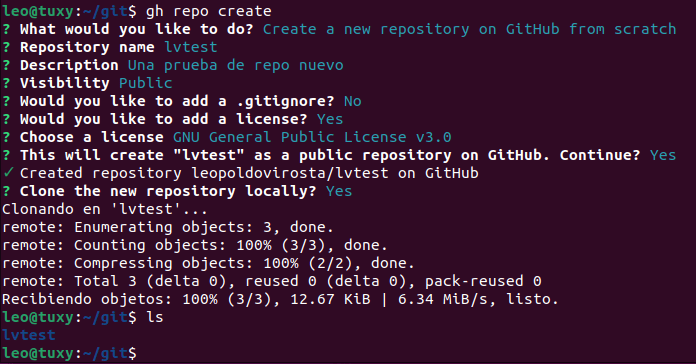
Primero vamos a crear un directorio llamado git y entramos en el. Una vez dentro empezamos con la instrucción gh repo create.
Le damos un nombre, descripción, añadimos una licencia si queremos, y lo clonamos para que aparezca en nuestro directorio git.
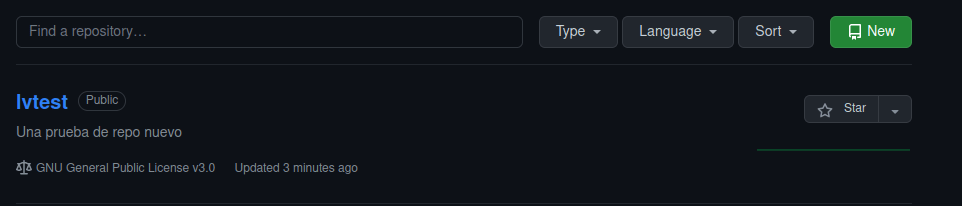
Si vamos a la web de Github vemos que ha creado el nuevo repositorio.
En el directorio git de nuestro equipo vemos que ha creado un archivo LICENSE
Subir archivo a nuestro repositorio en Github
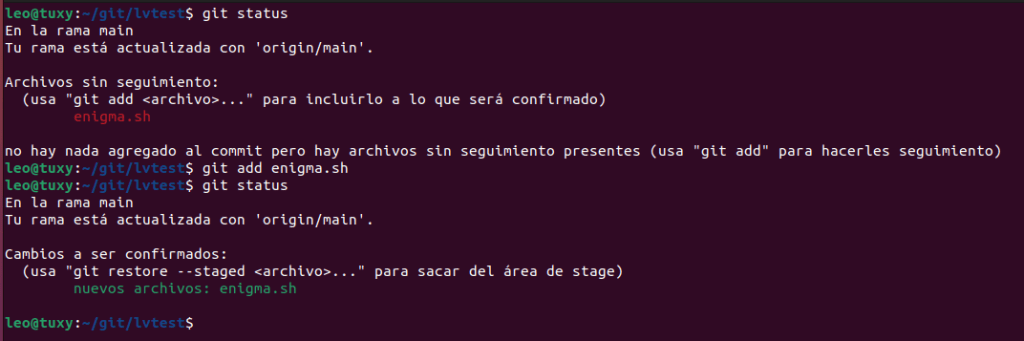
Una vez hemos creado nuestro primer archivo escribimos git add archivo. En todo momento podemos ver el estado con git status
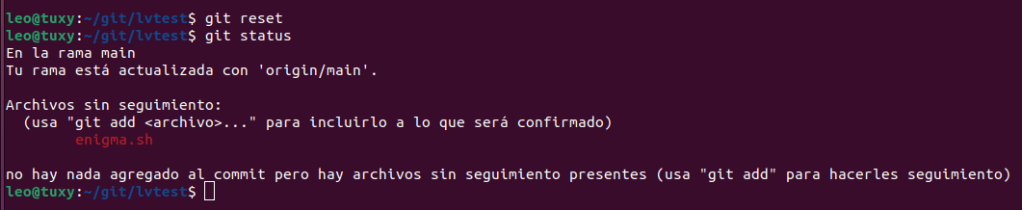
Si queremos deshacer algún cambio podemos hacerlo con git reset
Una vez añadidos el archivo o los archivos usamos git commit para guardar los cambios, y de paso podemos añadir una descripción de los cambios que hemos hecho.
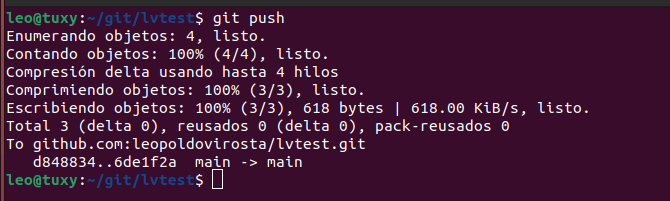
Para enviarlo a Github usamos git push
Si voy a Github podemos ver los cambios
Por lo general trabajamos los archivos desde nuestro ordenador y luego los subimos a Github, pero también es posible hacerlo a la inversa, aunque esto no es recomendable. Vamos a entrar en nuestro archivo y a editarlo. Para ello pinchamos en el símbolo del lápiz situado a la derecha.
Añadimos una línea nueva y pinchamos en Commit changes y aceptamos el nuevo commit
Ahora tenemos el archivo modificado pero en el repositorio de nuestro ordenador aún tenemos la versión anterior. Para actualizar los cambios en nuestro equipo usamos git pull origin main
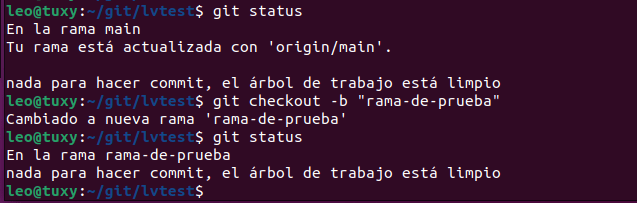
Crear una nueva rama
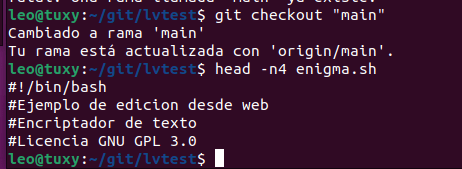
En caso de querer crear una nueva rama para hacer pruebas y que no interfiera en la rama main, la creamos con git checkout -b «nueva-rama»
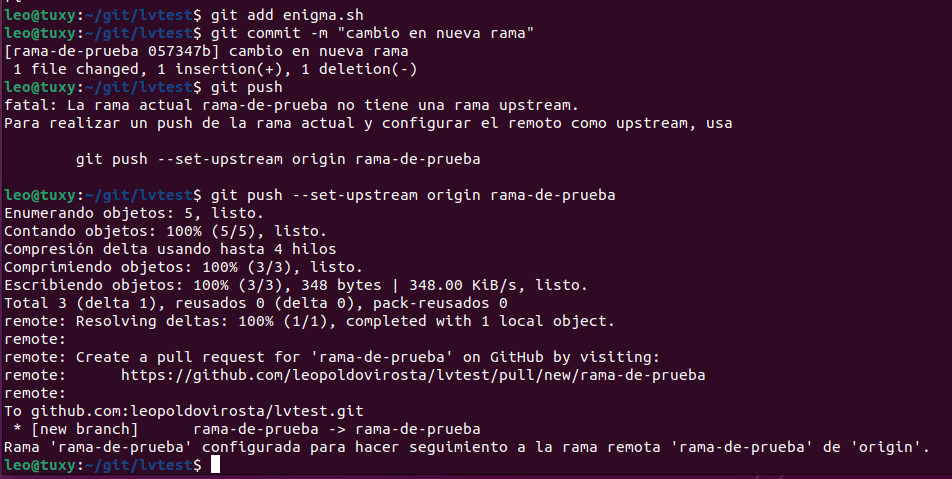
Si ahora hacemos un cambio en el archivo y lo intentamos subir a la nueva rama nos va a dar un error ya que la rama no existe, tendremos que hacer un git push como nos dice el mensaje de error (esto se hace solamente la primera vez). Una vez hecho ya tendremos la nueva rama creada, a partir de ahora podremos cambiar de rama con git checkout
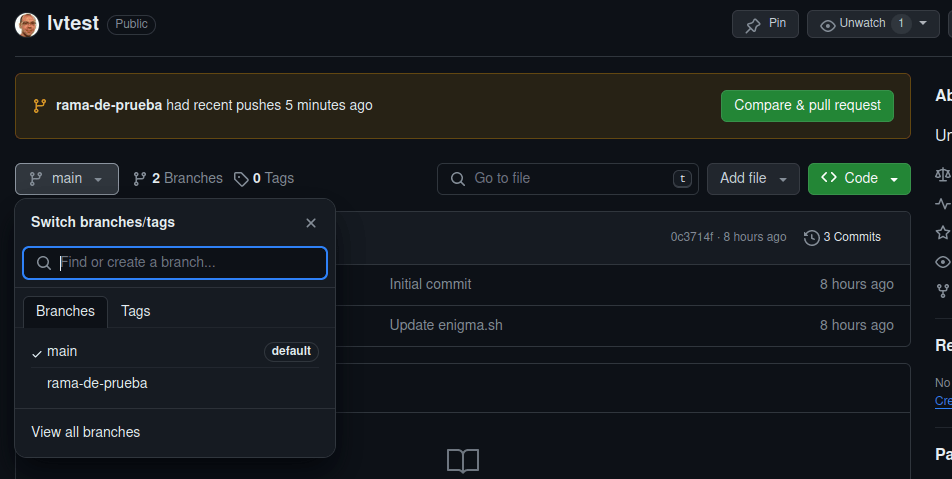
En la web podemos confirmar que se ha creado la nueva rama
En caso de que quiera enviar los cambios de la rama de prueba a la rama main, pinchamos a Compare & pull request
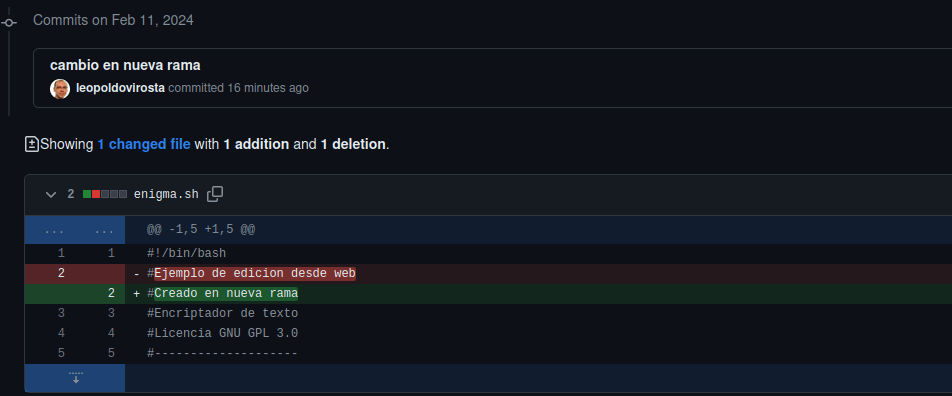
Abajo de la nueva pantalla podemos ver las modificaciones, en este caso una línea borrada y otra añadida
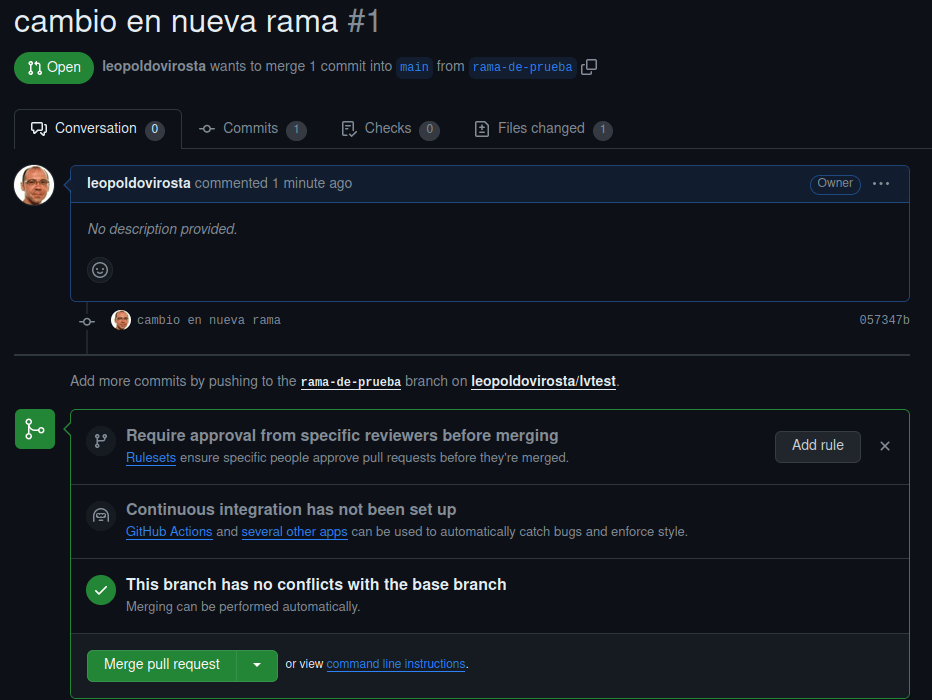
Pinchamos en Create pull request
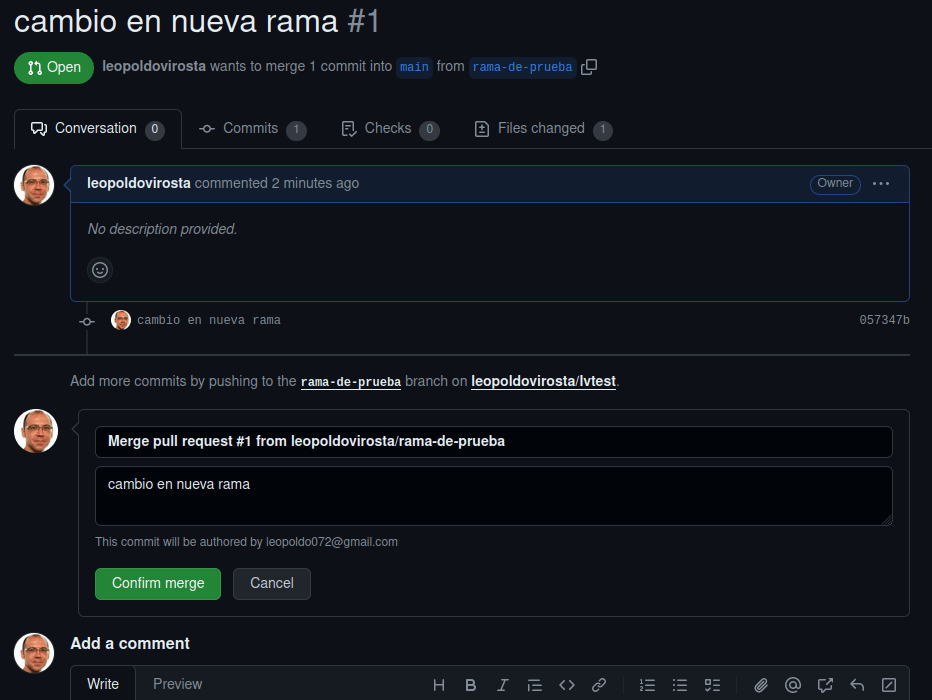
Y por último pinchamos en Merge pull request y posteriormente en Confirm merge
Una vez finalizado vemos que señala Merged y los cambios se han aplicado
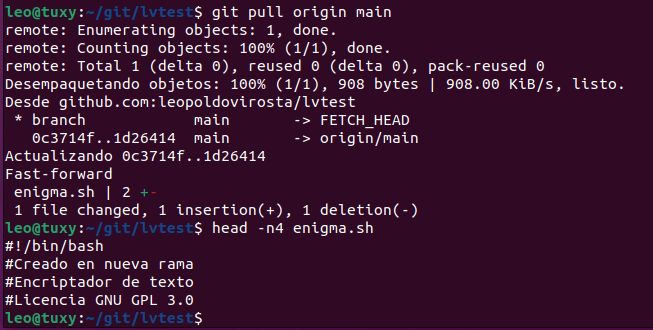
Sin embargo en nuestro ordenador aún no están actualizados los cambios, si vamos a la rama main podremos verlo
Para actualizar los cambios usamos git pull origin main
Clonar repositorio
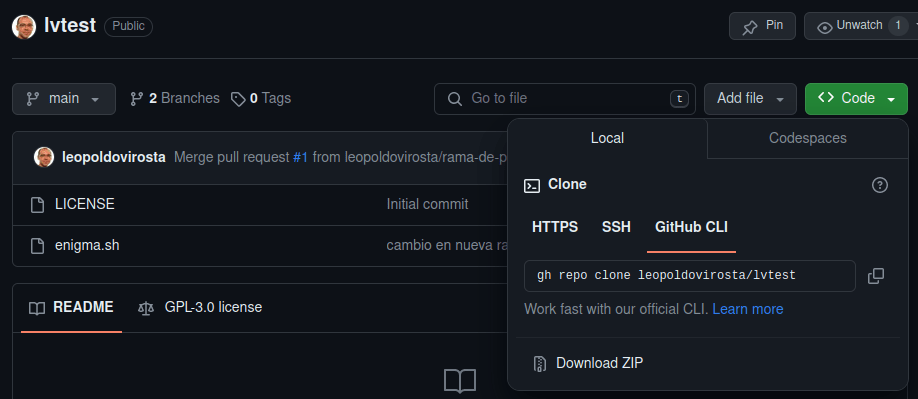
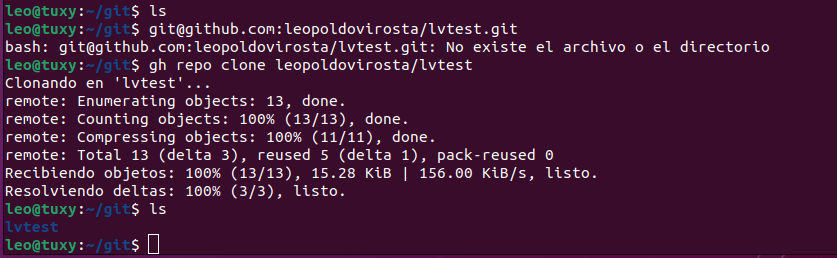
Si elimino el repositorio de mi ordenador por error puedo clonarlo desde el de Github, para ello voy a la pestaña Code y copio la dirección que hay en Clone
En la linea de comando copio la dirección y el repositorio se descarga de nuevo
Borrar archivo
Si quiero borrar un archivo y que se elimine en Github hacer un git rm, un commit y un push, y el archivo se habrá eliminado de mi equipo y de Github
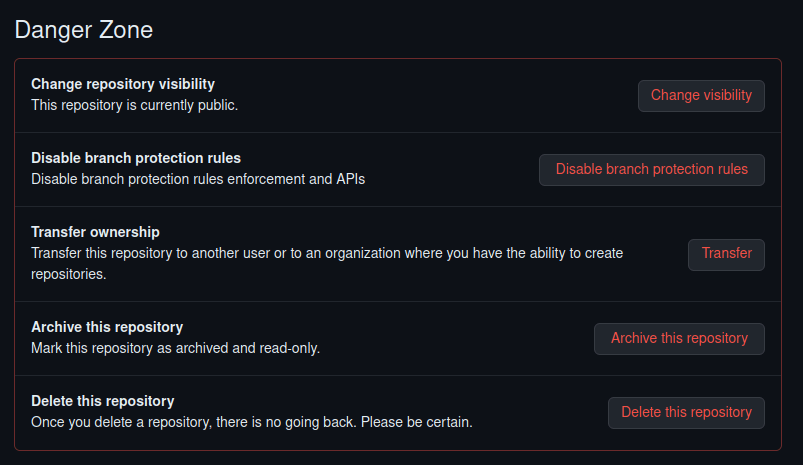
Eliminar repositorio
Si queremos eliminar un repositorio ir a Settings
Navegar hasta abajo a Danger Zone
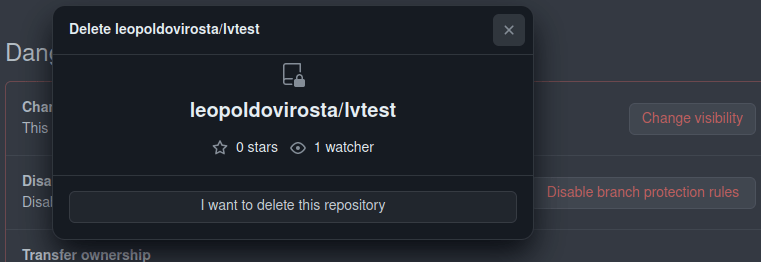
Pinchar en Delete this repository, después en I want to delete this repository
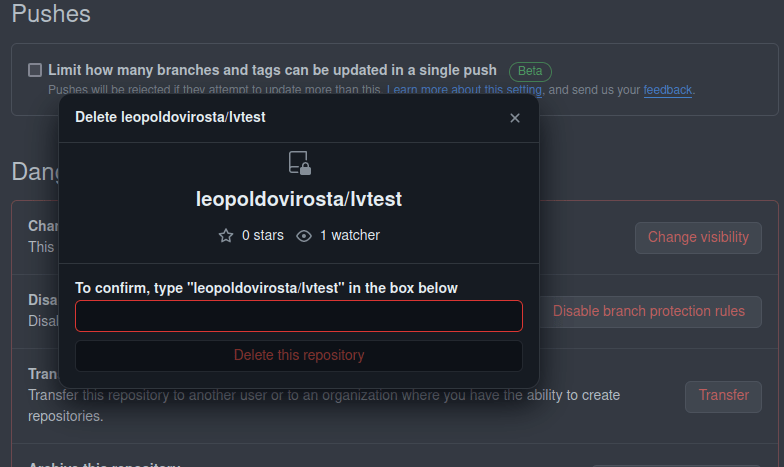
Pinchar en I have read and understand these effects
Y por último confirmar con el texto que nos pide